|
|
| (65 intermediate revisions by 3 users not shown) |
| Line 2: |
Line 2: |
|
| |
|
| ===Comparing Structure of Proteins=== | | ===Comparing Structure of Proteins=== |
| | |
| | '''Dali Results''' |
|
| |
|
| Dali shows a few proteins with similar structure to 1zkd. They are 2ex4 and 1im8 which shows the highest Z-value of 11.7 and 11.6 respectively. The higher the Z-value the more significant is the results. However, they are only 10-12% identical to the query protein. Nevertheless, these 2 proteins are used to compare with the query protein as these 10-12% identity may be at the binding site or ligand which will determine the functions. 2ex4 is a human methyltransferase with S-adenosylhomocysteine and 1im8 is found to be a methyltransferase with a bound S-adenosylhomocysteine from the crystal structure of YecO from Haemophilus influenzae (HI0319). | | Dali shows a few proteins with similar structure to 1zkd. They are 2ex4 and 1im8 which shows the highest Z-value of 11.7 and 11.6 respectively. The higher the Z-value the more significant is the results. However, they are only 10-12% identical to the query protein. Nevertheless, these 2 proteins are used to compare with the query protein as these 10-12% identity may be at the binding site or ligand which will determine the functions. 2ex4 is a human methyltransferase with S-adenosylhomocysteine and 1im8 is found to be a methyltransferase with a bound S-adenosylhomocysteine from the crystal structure of YecO from Haemophilus influenzae (HI0319). |
| Line 18: |
Line 20: |
| 9: 3027-A 2bzg-A 9.9 3.4 182 226 13 0 0 20 S TRANSFERASE thiopurine s-methyltransferase (thiopurine | | 9: 3027-A 2bzg-A 9.9 3.4 182 226 13 0 0 20 S TRANSFERASE thiopurine s-methyltransferase (thiopurine |
| 10: 3027-A 2aot-A 9.8 4.3 182 285 13 0 0 23 S TRANSFERASE histamine n-methyltransferase (hmt) (homo | | 10: 3027-A 2aot-A 9.8 4.3 182 285 13 0 0 23 S TRANSFERASE histamine n-methyltransferase (hmt) (homo |
| | |
| | '''Alignment with Known Proteins''' |
|
| |
|
| 1zkd is an unknown protein, and by using proteins similar to it, the functions of this unknown protein can be predicted. With 2ex4 and 1im8 showed by Dali to be the most similar, other tools are used to determine the similarity. Combinatorial Extension Method is used. Below shows the sequence alignment and structure alignment of the unknown protein with the proteins obtained from dali: | | 1zkd is an unknown protein, and by using proteins similar to it, the functions of this unknown protein can be predicted. With 2ex4 and 1im8 showed by Dali to be the most similar, other tools are used to determine the similarity. Combinatorial Extension Method is used. Below shows the sequence alignment and structure alignment of the unknown protein with the proteins obtained from dali: |
| | |
| | '''2ex4''' |
|
| |
|
| Alignment with 2ex4 | | Alignment with 2ex4 |
| Line 32: |
Line 38: |
| 1ZKD:A 251/252 GDTFQAIASHSYADPLQHPGRADLTAHV---DFDALGRAAESIGARAHGPVTQG | | 1ZKD:A 251/252 GDTFQAIASHSYADPLQHPGRADLTAHV---DFDALGRAAESIGARAHGPVTQG |
| 2EX4:A 191/175 GVILDD---------------VDSSVCRDLDVVRRIICSAG---LSLLAEERQE | | 2EX4:A 191/175 GVILDD---------------VDSSVCRDLDVVRRIICSAG---LSLLAEERQE |
| | |
| | [[Image:2ex4 jmol.JPG|thumb|250px|Figure 3. Structure of 2ex4|left]] |
| | |
| | [[Image:Structure aling.JPG|thumb|300px|Figure 4. Structure Alignment with 2ex4 (Blue:1zkd, Purple: 2ex4)|left]] |
| | |
| | Alignment Length: 294 |
| | |
| | Gaps (average per molecule): 53.5 |
| | |
| | Sequence Identity: 14.4% |
| | |
| | RMSD min – max: 3.03A |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | '''1im8''' |
|
| |
|
| Alignment with 1im8 | | Alignment with 1im8 |
| Line 43: |
Line 86: |
| 1IM8:A 157/155 ---NPNGVLVLSEKF | | 1IM8:A 157/155 ---NPNGVLVLSEKF |
|
| |
|
| [[Image:Structure aling.JPG|thumb]] | | [[Image:1im8 jmol.JPG|thumb|250px|Figure 5. Structure of 1im8|left]] |
| | |
| | [[Image:Structure alig.JPG|thumb|300px|Figure 6. Structure Alignment with 1im8(Blue:1zkd, Purple: 1im8)|left]] |
| | |
| | |
| | Alignment Length: 195 |
| | |
| | Gaps (average per molecule): 38.5 |
| | |
| | Sequence Identity: 11% |
| | |
| | RMSD min – max: 2.3A |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
|
| |
|
| Structure Alignment with 2ex4 (Blue:1zkd, Purple: 2ex4)
| |
|
| |
|
| Alignment Length: 294
| |
|
| |
|
| Gaps (average per molecule): 53.5
| |
|
| |
|
| Sequence Identity: 14.4%
| |
|
| |
|
| RMSD min – max: 3.03A
| |
|
| |
|
|
| |
|
| Line 61: |
Line 120: |
|
| |
|
|
| |
|
| | ===Ligand and Binding Sites=== |
|
| |
|
| | [[Image:Binding sites.JPG|thumb|600px|Figure 7. Binding Sites|left]] |
|
| |
|
|
| |
|
|
| |
|
|
| |
|
| [[Image:Structure alig.JPG|thumb|Structure Alignment with 1im8]]
| |
|
| |
|
| Structure Alignment with 1im8 (Blue:1zkd, Purple: 1im8)
| |
|
| |
|
| Alignment Length: 195
| |
|
| |
|
| Gaps (average per molecule): 38.5
| |
|
| |
|
| Sequence Identity: 11%
| |
|
| |
|
| RMSD min – max: 2.3A
| |
|
| |
|
|
| |
|
| Line 91: |
Line 146: |
|
| |
|
|
| |
|
| ===Ligand and Binding Sites===
| |
|
| |
|
| [[Image:Binding sites.JPG|thumb|Binding Sites]]
| |
|
| |
|
| [[Image:Ligand.JPG|thumb|Conserved regions]]
| |
|
| |
|
|
| |
|
| Line 135: |
Line 187: |
|
| |
|
|
| |
|
| | [[Image:Ligand.JPG|thumb|400px|Figure 8. Conserved regions|left]] |
|
| |
|
|
| |
|
| Line 147: |
Line 200: |
|
| |
|
|
| |
|
| ===Surface Properties===
| |
|
| |
|
| Red shows negatively charge and blue shows positively charge
| |
| [[Image:Surface_charge.JPG|thumb|Surface Charges of Protein]]
| |
|
| |
|
|
| |
|
| Line 179: |
Line 229: |
|
| |
|
| ===Domain=== | | ===Domain=== |
| | |
| | '''InterPro Results''' |
|
| |
|
| [[Image:InterPro.JPG|Thumb|InterPro Scan Results|Left]] | | [[Image:InterPro.JPG|Thumb|InterPro Scan Results|Left]] |
|
| |
|
|
| |
|
| Domain Identification Using Pfam
| | '''Pfam Results''' |
|
| |
|
| DUF185: domain 1 of 1, from 64 to 299: score 227.1, E = 3.9e-65 | | DUF185: domain 1 of 1, from 64 to 299: score 227.1, E = 3.9e-65 |
| Line 208: |
Line 260: |
| query 276 AHVDFDALG------RAAESIG-ARAHGPVT 299 | | query 276 AHVDFDALG------RAAESIG-ARAHGPVT 299 |
|
| |
|
| Domain DUF 185 has been identified by InterPro and Pfam as show above. In Pfam the E value of 3.9e-65 gives significant results showing that it is not by chance nor random that the match made was DUF185. However not much is known about DUF 185. | | Domain DUF 185 has been identified by InterPro and Pfam as show above. In Pfam the E value of 3.9e-65 gives significant results showing that it is not by chance nor random that the match made was DUF185. DUF 185 belong to the family of RNA methyltransferase. |
| | |
| | |
|
| |
|
| ==Function of Hypothetical Protein LOC55471 Isoform 1== | | ==Function of Hypothetical Protein LOC55471 Isoform 1== |
| Line 216: |
Line 266: |
| ===ProFunc analysis reveals methyltransferase activity as the most likely biochemical function=== | | ===ProFunc analysis reveals methyltransferase activity as the most likely biochemical function=== |
| By using ProFunc (Laskowski et al, 2005) the most likely biochemical function of the unknown bacterial Protein 1zkd was determined as Methyltransferase. | | By using ProFunc (Laskowski et al, 2005) the most likely biochemical function of the unknown bacterial Protein 1zkd was determined as Methyltransferase. |
| Matching structures were determined by SSM Secondary Structure Matching (Krissinel & Henrick, 2004) showing possible matches with 9 Methyltransferases from both human and bacteria (Fig.1). | | Matching structures were determined by SSM Secondary Structure Matching (Krissinel & Henrick, 2004) showing possible matches with 9 Methyltransferases from both human and bacteria (Fig.9). |
|
| |
|
|
| |
|
| [[Image:Image001.png|thumb|600px|Figure 1. SSM results showing ten sequences with a sequences id around 20 % with higher matching folds.|center]] | | [[Image:Image001.png|thumb|600px|Figure 9. SSM results showing ten sequences with a sequences id around 20 % with higher matching folds.|center]] |
|
| |
|
|
| |
|
| Ligand Template Matches LIG (Laskowski et al, 2005) revealed a probable match with the Protein-l-isoaspartate o-methyltransferase 1dl5 (Fig.2). | | Ligand Template Matches LIG (Laskowski et al, 2005) revealed a probable match with the Protein-l-isoaspartate o-methyltransferase 1dl5 (Fig.10). |
|
| |
|
| [[Image:Image003.png|thumb|600px|Figure 2. LIG results support the hypothesis of 1zkd being a methyltransferase.|center]] | | [[Image:Image003.png|thumb|600px|Figure 10. LIG results support the hypothesis of 1zkd being a methyltransferase.|center]] |
|
| |
|
|
| |
|
| REV Reverse Template Matches (Laskowski et al, 2005) also showed probable matches for several methyltransferases (Fig.3). | | REV Reverse Template Matches (Laskowski et al, 2005) also showed probable matches for several methyltransferases (Fig.11). |
|
| |
|
|
| |
|
| [[Image:Image005.png|thumb|600px|Figure 3. REV results showing five probable matches, which are all methyl or dimethyltransferases.|center]] | | [[Image:Image005.png|thumb|600px|Figure 11. REV results showing five probable matches, which are all methyl or dimethyltransferases.|center]] |
|
| |
|
|
| |
|
| Line 237: |
Line 287: |
| ===Genomic context of the 1izkd gene=== | | ===Genomic context of the 1izkd gene=== |
|
| |
|
| Genomic context of 1zkd in the genome of Rhodopseudomonas palustris from the NCBI Entrez Gene database shows a genomic co-localisation with another transferase, an oxidase, a kinase and another hypothetical protein (Fig.4). | | Genomic context of 1zkd in the genome of Rhodopseudomonas palustris from the NCBI Entrez Gene database shows a genomic co-localisation with another transferase, an oxidase, a kinase and another hypothetical protein (Fig.12). |
|
| |
|
|
| |
|
| [[Image:Image007.png|frame|center|Figure 4. The RPA4359 gene of the protein 1zkd is co-located with an upstream prolipoprotein diacylglyceryl transferase gene (1gt) and downstream with a multicopper polyphenol oxidase (RPA4360), a ribose-phosphate pyrophosphokinase (ribP) and another hypothetical protein of unknown function gene (RPA4361).]] | | [[Image:Image007.png|frame|center|Figure 12. The RPA4359 gene of the protein 1zkd is co-located with an upstream prolipoprotein diacylglyceryl transferase gene (1gt) and downstream with a multicopper polyphenol oxidase (RPA4360), a ribose-phosphate pyrophosphokinase (ribP) and another hypothetical protein of unknown function gene (RPA4361).]] |
|
| |
|
| ===Localisation of 1zkd orthologs in the cell=== | | ===Localisation of 1zkd orthologs in the cell=== |
| Line 251: |
Line 301: |
| ===Expression profiles of mouse and human orthologs=== | | ===Expression profiles of mouse and human orthologs=== |
|
| |
|
| Expression profile data of the mouse and human ortholog were suggested by analysis of EST counts from NCBI UniGene database (http://www.ncbi.nlm.nih.gov/sites/entrez?db=unigene). ESTs were found in diverse tissues including brain, liver, lung, muscle and endocrine system showing that the target protein is expressed in a wide range of different cells (Fig.5a,b). | | Expression profile data of the mouse and human ortholog were suggested by analysis of EST counts from NCBI UniGene database (http://www.ncbi.nlm.nih.gov/sites/entrez?db=unigene). ESTs were found in diverse tissues including brain, liver, lung, muscle and endocrine system showing that the target protein is expressed in a wide range of different cells (Fig.13a,b). |
| | |
| | [[Image:Image009.png|left|thumb|300px|Figure 13a. Expression profile of the mouse ortholog.]] |
| | [[Image:Image011.png|none|thumb|300px|Figure 13b. Expression profile of the human ortholog.]] |
| | |
| | ===Electrostatic properties of the 1zkd protein surface=== |
| | |
| | Electrostatic properties and surface charges of 1zkd were modelled using Adaptive Poisson-Boltzmann Solver APBS (Baker et al, 2001) and visualisation was performed by using Pymol (http://www.pymol.org). According to the resulting model, the 1zkd protein got a mostly negatively charged surface (Fig.14a,b), indicating that interactions with the negatively charged backbone of nucleic acids are rather unlikely. |
| | |
| | [[Image:Surface charges 1zkd.PNG|left|thumb|500px|Figure 14a. Surface charges of 1zkd as a dimer. Red colour indicating negative charges, blue colour indicating positive charges.]] |
| | |
| | [[Image:Surface_charge.JPG|left|thumb|300px|Figure 14b. Surface Charges of Protein. Red colour indicating negative charges, blue colour indicating positive charges]] |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
|
| |
|
| [[Image:Image009.png|left|thumb|300px|Figure 5a. Expression profile of the mouse ortholog.]]
| |
| [[Image:Image011.png|none|thumb|300px|Figure 5b. Expression profile of the human ortholog.]]
| |
|
| |
|
|
| |
|
|
| |
|
| ===Electrostatic properties of the 1zkd protein surface===
| |
|
| |
|
| Electrostatic properties and surface charges of 1zkd were modelled using Adaptive Poisson-Boltzmann Solver APBS (Baker et al, 2001) and visualisation was performed by using Pymol (http://www.pymol.org). According to the resulting model, the 1zkd protein got a mostly negatively charged surface (Fig.6), indicating that interactions with the negatively charged backbone of nucleic acids are rather unlikely.
| |
|
| |
|
|
| |
|
|
| |
|
| == Evolution of Hypothetical Protein LOC55471 Isoform 1 ==
| |
|
| |
|
| BLASTP results produced 47 multiple aligned sequences to the bacterial sequence of the 1ZKD protein.
| |
| The results are as follow
| |
|
| |
|
| >gi|9294283|dbj|BAB02185.1| unnamed protein product [Arabidopsis thaliana]
| |
| MEEVLTNPKAGFYMNRDVFGAQGDFITSPEVSQMFGEMIGVWTVCLWEQMGRPERVNLVELGPGRGTLMA
| |
| DLLRGTSKFKNFTESLHIHLVECSPALQKLQHQNLKCTDESSSEKKAVSSLAGTPVHWHATLQEVPSGVP
| |
| TLIIAHEFYDALPVHQFQTQYLQKSTRGWCEKMVDVGEDSKFRFVLSPQPTPAALYLMKRCTWATPEERE
| |
| KMEHVEISPKSMDLTQEMAKRIGSDGGGALIIDYGMNAIISDSLQAIRKHKFVNILDDPGSADLSAYVDF
| |
| PSIKHSAEEASENVSVHGPMTQSQFLGSLGINFRVDALLQNCNDEQAESLRAGYWQLVGDGEAPFWEGPN
| |
| EQTPIGMGTRYLAMSIVNKNQGIPAPFQ
| |
|
| |
|
| >gi|50550583|ref|XP_502764.1| hypothetical protein [Yarrowia lipolytica]
| |
| MLRTIRPARTTLVRAVRPVRPVSGRVGRLGRHVTTGTTSSTTSASSPDLSTTLAMAIEQQGPMSVATFMK
| |
| HCLTNPSGGYYIDKDPLGAKGDFTTSPEISQMFGELVGLWLAAQWLYYGQKQPFRVIEYGPGRGTLMDDS
| |
| LRALVSAKSTGAKEALKEVLLVEASPVLRDAQRKKLCGAESQFKTEEDGSITCVTKYGVPIRWYEDSKML
| |
| DKLASSNDPLHNYIVAHEFFDALPIYQFEKTDKGWRELMVNYGVENKTKESSILLPGQTHIKSSDLDKDK
| |
| KKTFHLVTAPTWTVASKVIPQSHKRYRDLPEWSKIEVCPDAWDVANQMGRLVAKGGAAFIVDYAVKPGVP
| |
| VNTLRGIRDHKICSPFEEPGKVDLSADVDFTAIGIASRSKNKENVSAFGPINQATWLKNMGIEMRTEKLM
| |
| EGKEEYIKKRIESQYKRLVDIGINGMGKIYKAFFLTHSSHGYPVGFPIPEPKDLKEPHQKPEKDPKDTEP
| |
| KVVEV
| |
|
| |
|
| >gi|27382556|ref|NP_774085.1| hypothetical protein blr7445 [Bradyrhizobium japonicum USDA 110]
| |
| MTEQPLLNEIKALIKSSGPMPVWRYMELCLMHPRYGYYVSRDPLGREGDFTTAPEVSQMFGELLGLWTAS
| |
| VWKQMGSPQSLRLIELGPGRGTMMADALRALRVLPPLYQALQIHLVEVNPVLRERQSATLSGARNVAWHD
| |
| SIDDVPEGPSIILANEYFDVLPIHQMVKRENGWHERVIEIDPNGKLQFGAASEPTPRFDVLLPPLVRAAP
| |
| VGAVFEWRPDGEVMKLATRVRDQDGAALIIDYGHLRSDAGDTFQAIARHTFTDPLKAPGQADVTAHVDFQ
| |
| ALARAAEDVGARVHGPVTQGDFLKRVGIDTRAAALMQKATPEVATDISVALKRLTDTGRSGMGSMFKVLG
| |
| ISEPRLTGLAGLSDLEHAGGN
| |
|
| |
|
| >gi|119177909|ref|XP_001240685.1| hypothetical protein CIMG_07848 [Coccidioides immitis RS]
| |
| MSNGATQIVNRLARASRCSRLATPSAAKRYLSSAPQRRWSTPLAKTIADVINTAGPISIAAYMRQCLTSP
| |
| EGGYYTSRGSTGVEVFGRKGDFVTSPEISQMFGELLGVWMVTEWMAQGRRSRGVQLIEVGPGRGTLMADM
| |
| LRSVRNFKSFSSSIEAVYLVEASPTLRDIQKQMLCGDAPMEEIEVGYRSTSKHLGVPVVWTEHIRSLPQG
| |
| DNDVPFIIAHEFFDALPIHAFQCVASPPSETIITPTGPTTLRQPLSSSPTQWRELVVSVNPASQMHAENR
| |
| LEFRLSLAKTSTPASMVMPEMSERYKALKSTRGSTIEISPESQGYVQEFARRIGGHSNSKIPTTRKPAGA
| |
| ALILDYGPSHSIPVNSLRGIKDHKLVSPFTSPGQVDLSADVDFIALADSAISASPGVEVHGPTEQGSFLH
| |
| SLGISERAAQLMKRAEDETKRKNIEAGWKRLVERGGGGMGRIYKAMAIIPEAGGMRRPVGFGGQVPA
| |
|
| |
|
| >gi|91978339|ref|YP_570998.1| protein of unknown function DUF185 [Rhodopseudomonas palustris BisB5]
| |
| MTDNSPLLAEIKRLIKSTGPMPVWRYMELCLNHPLYGYYVSRDPLGREGDFTTSPEISQMFGELIGLWAA
| |
| SVWKATGEPDVLRLIEIGPGRGTMIADALRALRVLPPLYQSLSVHLVEINPVLREKQKATLAGIRNIHWH
| |
| DTFADVPDGPAVILANEYFDVLPIHQAVKRDGGWHERVIEISASGELVFGVAPDPIPRFDILLPHLVRMA
| |
| PAGAVFEWRSDAEIMAIATRLRDQGGAALIIDYGHIRSDVGDTFQAIARHSFADPLQNPGRADLTAHVDF
| |
| QALGRAAEDVGARLHGPVTQGEFLKRLGIETRALSLMAKASPQVSEDISGALRRLTGEGRGAMGSMFKVI
| |
| GVSDPNITSLVALSDDAERAAEGQPA
| |
|
| |
|
| >gi|46200845|ref|ZP_00207869.1| COG1565: Uncharacterized conserved protein [Magnetospirillum magnetotacticum MS-1]
| |
| MSLSALLSERIKATGPIPVSEFMAEALGHPEYGYYRGRDPFGMAGDFTTAPEISQMFGELIGLWCALVWQ
| |
| SMGSPERVVLAEIGPGRGTLMADLLRAAKALAPFARALDVHLIETSPSLRNRQAQALADQSVTWHERFED
| |
| LPDGPLLLVANELFDALPIRQLEKVGGVWHERVVGLDDQGALVLALGPVVADPPLAPAVLNAPDGSLAEV
| |
| CPQGRVLAEAVARRLAHQGGAALIIDYGYETSAAGDSLQAVKSHRHHPVLSAPGTADITAHVDFQALAEA
| |
| ASGLARVYGPVPQGRFLARLGLEERVRMLMQHASVEQAAHLASGARRLIDPAEMGTLFKVLALANPLLPA
| |
| PPGLELA
| |
|
| |
|
| >gi|125526627|gb|EAY74741.1| hypothetical protein OsI_002588 [Oryza sativa (indica cultivar-group)]
| |
| MEEVLTNPQSGFYINRDVFGTSGDFITSPEVSQMFGEMTGVWAMCLWEQMGQPEKVNLIELGPGRGTLLA
| |
| DLLRGSSKFVNFTKALNINLVECSPTLQKVQYNTLKCEDEPIGDKTRTVSKLCGAPVHWHASLEQVPSGL
| |
| PTIIIAHEFYDALPIHQFQPTASLLFLSKRCGWASSEELEKVEHIEVCPKAMEITEQIADRISSDGGGAL
| |
| IIDYGKDGIVSDSLQAIRKHKFVHILDNPGSADLSAYVDFASIRHSAKEASDDISVHGPMTQSQFLGSLG
| |
| INFRVEALLQNCATDEQAESLRTGYWRLVGDGEAPFWEGPDDQTPIGMGTRYLAMAIVNKKQGTPVPFE
| |
|
| |
|
| >gi|119480871|ref|XP_001260464.1| conserved hypothetical protein [Neosartorya fischeri NRRL 181]
| |
| MMNSATKRALTRHFRTYQCRNLQIGSHRCSSTFDQRQWSTPLAKTLANAIKVTGPIPIAAFMRQVLTSPE
| |
| GGYYTTRPEGGGEVFGKKGDFVTSPEISQVFGELVGIWTITEWMAQGLKRSGVQLIEVGPGKGTLMDDML
| |
| RTFRNFKSFASSLEAIYLVEASPTLREVQKQRLCGDAAMEETDIGHKSISKYFNVPVIWVEDIRLLPHEE
| |
| DKTPFIFAHEFFDALPIHAFESIPPAPENQSEQKEIMTPTGPAKLHQPMKPANTPQWREIMVTLNPKAVE
| |
| ENIEGEPEFKLTLAKASTPSSLVIPEISERYRKLKSTPGSTIEVSPESRIYASDFARRIGGSSQPPRTVG
| |
| SRNAPAAQPKKVPSGAALIMDYGTMSTIPINSLRGIQHHRTVPALSSPGQVDVSADVDFMALAEAAIEAS
| |
| EGVEVHGPVEQGDFLQVMGIAERMQQLLKGVQDEEKRKTLESGWKRLIERGGGGMGKIYKFMAIIPENGG
| |
| RRRPVGFGGSVQM
| |
|
| |
|
| >gi|92118562|ref|YP_578291.1| protein of unknown function DUF185 [Nitrobacter hamburgensis X14]
| |
| MTEASPLLPDIKKLIKTSGPLPVWRYMQLCLTHPEHGYYIARDPLGREGDFITSPEVSQMFGELIGLWAA
| |
| SVWRAMGSPTTLRLIELGPGRGTMMADALRALRVLPPMHQALSVHLVEINPVLREKQKAALSDARTIQWH
| |
| ASLDEVPQGPAIILANEYFDVLPVHQMVKRDDGWYERVVDIDGSGQLVFGTTAAPTPRFDALLPPLVRAA
| |
| PVGAIFEWRPDAEMMTIATRVRDHGGAALIIDYGHVRSDAGDTFQAIAGHSFADPLKYPGQADVTAHVDF
| |
| QALARAAEDIGARVHGPVTQGEFLQRLGIEARAVNLMAKATPEISEGISTALKRLTEGGRGGMGSMFKAI
| |
| GVSDSSLTELAGLSDRKRRGGIRAP
| |
|
| |
|
| >gi|146342824|ref|YP_001207872.1| hypothetical protein BRADO6003 [Bradyrhizobium sp. ORS278]
| |
| MIETSPLQPEIKRLIKASGPMPVWRYMELCLMHPEHGYYISRDPLGREGDFTTAPEVSQMFGELLGLWAA
| |
| SIWKAAGSPQQFRLIELGPGRGTMMSDALRALRVLPPLYQTISVHLVEINPVLREKQKATLTGLRNVTWH
| |
| DSFDEVPEGPSVIFANEYFDVLPVHQMVRRETGWHERVVELDDDENFVYGTAADPTPGFELLLSPLVRAA
| |
| PAGAIFEWRPDTQMMAIARRLREQRGAAVIIDYGHVRSDVGDTFQAIARHSFADPLKTPGLADITAHVDF
| |
| DALSRTAEAVGARVHGPITQGEFLQRLGIETRALTLMQKASPEVSEDIASGLKRLTSGGRGGMGSLFKVL
| |
| GVSDPSIPVLAGISDEHTSEKTGGA
| |
|
| |
|
| >gi|146322884|ref|XP_755307.2| DUF185 domain protein [Aspergillus fumigatus Af293]
| |
| MNSATKSAWTRHFRTYQYRNLRIGSHRCSSTFEKRQWSTPLAKTLANAIKVTGPIPIAAFMRQVLTSPEG
| |
| GYYTTRPEGGGEVFGKKGDFVTSPEISQVFGELVGIWTITEWMAQGSKRSGVQLIEVGPGKGTLMDDMLR
| |
| TFRNFKSFASSLEAIYLVEASPTLREVQKQRLCGDAAMEETDIGHKSISKYFNVPVLWVEDIRLLPHEED
| |
| KTPFIFAHEFFDALPIHAFESIPPAPENSPEQKEIITPTGPAKLHQPMKPANTPQWREIMVTLNPKAVED
| |
| NIEGEPEFKLTLAKASTPSSLVIPEISERYRKLKSTPGSTIEVSPESRIYASDFARRIGGSSQPPRTVGS
| |
| RNSPAAQPKKIPSGAALIMDYGTMSTIPINSLRGIQHHRTVPALSSPGQVDVSADVDFMALAEAAIEASE
| |
| GVEVHGPVEQGDFLQVMGIAERMQQLLRGVQDEEKRKTLESGWKRLIERGGGGMGKIYKFMAIIPENGGR
| |
| RRPVGFGGTVQM
| |
|
| |
|
| >gi|78693301|ref|ZP_00857815.1| conserved hypothetical protein [Bradyrhizobium sp. BTAi1]
| |
| MIELSPLHSEIKRVIKASGPMPVWRYMELCLMHPEHGYYISRDPLGREGDFTTAPEVSQMFGELLGLWAA
| |
| SVWKASGSPQQFRLIELGPGRGTMMSDALRALRVLPPLYQTISVHMVEINPVLREKQKATLTGLRNITWH
| |
| ESFDDVPEGPSVIFANEYFDVLPIHQMLKRETGWHERVVELDAEENFAYGTAAEPTPGFELLLPPLVRAA
| |
| PLGAIFEWRPNNEIMAIAKRIREQRGAAVIIDYGHVRSDVGDTFQAIARHSFADPLKTPGLADITAHVDF
| |
| EALARAADAVGARVHGPITQSEFLRRLGIETRALTLMQKASPDISRDIASGLKRLIEGGRGGMGSLFKVL
| |
| GLSDASIPVLAGISDEHTGGKPGGA
| |
|
| |
|
| >gi|84499690|ref|ZP_00997978.1| hypothetical protein OB2597_07165 [Oceanicola batsensis HTCC2597]
| |
| MAVTPLLDRIRHRIGAQGPMTLAEYMQIALLDPDHGYYATRDPFGTAGDFITAPETSQMFGELVGLALAQ
| |
| SWIDQGRPAPFILAEPGPGRGTLMADILRATRSVPGFHDGLSLVLIEASPVLRDIQARTLSGYRAEWIDD
| |
| LGALPEAPLFLVANEFFDALPIRQFRRRGDGWAEVMVTVSGSGLATALAAPVPLPELAHRLGDTREDDVV
| |
| ELCPAAARAAAHIGARIADQGGAAVIVDYGDWRSLGDTFQALKGHAPVDPLAAPGTADLTAHVDFERLAK
| |
| AATPAWASGMIPQGVFLERLGITARAQALATRLQGPDLDAHVAAHRRLTHPEEMGTLFKVLALSPPDAPP
| |
| VPGTTDPEWPTE
| |
|
| |
|
| >gi|67539742|ref|XP_663645.1| hypothetical protein AN6041.2 [Aspergillus nidulans FGSC A4]
| |
| MNCSTQRIVNQFSRQTARRRFNIRSRRWNSTFETREWSTPLARTLANVIKTTGPVPIAAFMRQVLTSPEG
| |
| GYYTTKPGGGGEVFGKKGDFVTSPEISQVFGELVGIWTIAEWMAQGGKKSGVQLMEIGPGKGTLMDDMLR
| |
| TFRNFKPFTSSLEAIYLVEASPTLREVQKQLLCGNAVMEETDIGHRCTSKYFNVPVIWVEDIRLLPHEED
| |
| KTPFIFAHEFFDALPIHAFESVPPSPENEQQEQEIMTPTGRTKLQRPPKAANTPQWRELMVTLNPKAVDE
| |
| NIKDEPEFKLTLAKASTPSSLVIPEISERYRALKSQPGSTIEVSPESRIYASDIARRIGGSSQPPRTAAG
| |
| RNASAPSAIAKRIPSGAALIMDYGTMSTVPINSLRGIQNHKIVPALSSPGRVDVSADVDFTSLAEAALEA
| |
| SEGVEVHGPVEQGHFLQAMGIAERMQQLLSTVKDEKKRKILETGWQRLVERGGGGMGKLYKVMTIIPENG
| |
| GRRRPVGFGGGVPL
| |
|
| |
|
| >gi|85716018|ref|ZP_01046995.1| hypothetical protein NB311A_14415 [Nitrobacter sp. Nb-311A]
| |
| MTEPAPLLADIKRLIKTSGPLPVWRYMQLCLTHPEHGYYIARDPLGREGDFITSPEVSQMFGELLGLWGA
| |
| SVWRTIGSPLTLRLIELGPGRGTMMADALRALRVLPPMYESLSVHMVEINPVLREKQMAALSDAPNIQWH
| |
| ASLDEVPQGPAIIFANEYFDVLPVHQMVKGDDGWHERVVDIDGGQLVFGVSATPTPRFDVLLPPLVRAAP
| |
| VGAIFEWRPDAEIMSIATRVRDQGGAALIIDYGHERSDAGDTFQAIARHSFADPLKYPGRVDVTAHVDFE
| |
| ALARAAEDVGARVHGPVTQGEFLRRLGIEARAVNLMAKATAEVSDGIASALKRLTEGGRGGMGSMFKVIG
| |
| VSSPGLTELAGLSDRERRGGIKAP
| |
|
| |
|
| >gi|145252682|ref|XP_001397854.1| hypothetical protein An16g05460 [Aspergillus niger]
| | == Evolution of Hypothetical Protein LOC55471 Isoform 1 == |
| MNQATRRAVRQLLRKHPNQTLFLKSQRWSSTTPASSTSTSETRKWSTPLAQTLANAIKVTGPVPIAAFMR
| |
| QVLTNPEGGYYTTRPEGHGAVFGKKGDFVTSPEISQVFGELVGIWTIAEWMAQGRKRSGVQLMEVGPGKG
| |
| TLMDDMLRTFRNFKMFSSSMEAIYLVEASATLREVQKKLLCGDAVMEATDIGHKSTCKYFDVPIVWVEDI
| |
| RLLPHEEEKTPFIFAHEFFDALPIHAFESIPPSPENQPEQKEIMTPTGPAKLHQPLKPANTPQWREIMVT
| |
| LNPKAVEENIEGEPEFKLTLAKASTPSSLVIPEISPRYRALKSQPGSTIEVSPESRIYAADFARRIGGAS
| |
| EPPRTATKGAAASAPAPAKRVSSGAALIMDYGTLNTIPINSLRGIQEHKNVPPLSSPGQVDVSADVDFTA
| |
| LAEAAIEASEGVEVHGPVEQGDFLQAMGIEERMQQLLKKVEDEEKRKTLETGWKRLVEKGGGSMGKIYKV
| |
| MAIVPENDGKRRPIGFGGGLVM
| |
|
| |
|
| >gi|116058192|emb|CAL53381.1| ATP synthase beta subunit/transcription termination factor rho-like (ISS) [Ostreococcus tauri]
| |
| MGGGEHGKGERTGMIGHLKRAMAFAGGSIPVSEYVRECLTNPEHGYYMRGDVFGRDGDFVTSPEISQVFG
| |
| EVLGVWAALQHEALGSPGTLRVVEFGPGRGTLMADLLRGTSKFEKFRSAVSVHLIEVSPALREVQARTLR
| |
| CVDVETTSAAADDGGARVRVPKNALEAEEGEVDKRSAADGPSGEAHTRGTSEISGAKVFWHDGLESVPNG
| |
| PTLVICHEFFDALPVRQFQRTDRGWCEKLVTIDAELASTAETVEETTPRRELAMVLSPGPTPASHMLVPR
| |
| RLKGLPKEQVDSLRLLELSPPSMTLWDKLADRIEKNSGAVLAIDYGEEGPLGNTLEAIKDHKFVHVLDSP
| |
| GEADLSAYVDFGALRQIVEEKPQRGVTCYGPVTQQQLLLSLGLVARLEQLVENAASEDQANALVKGCERL
| |
| VGDGAGNAETGEPPGMGVRYKAMCMVSRGLPKPVGFS
| |
|
| |
|
| >gi|83309693|ref|YP_419957.1| hypothetical protein amb0594 [Magnetospirillum magneticum AMB-1]
| | === BLAST P === |
| MTLADILADRIRATGPIPVSEFMAEALGHPEYGYYMGRDPFGMAGDFITAPEISQMFGELIGLWCALVWQ
| |
| SMGAPKRVVLAEIGPGRGTLMADLLRAAQALPPFALALNVHLIETSPSLRNRQAQALTDRSVEWHERFED
| |
| LPDGPLLLVANELFDALPIRQLEKAGGVWRERVVALDEAGAFAFAQGPVVAEPPLAPAVLGAADGAVAEL
| |
| CPQGRALAGTIARRLAHQGGAALIIDYGYGKSAAGDSLQALKSHKRHPVLSGPGTADITAHVDFQALAEA
| |
| ASGLARAHGPVPQGSFLARLGLEERVRMLMQNATPEQAAHLASGARRLIDPGEMGTLFKVLALAAPLLPV
| |
| PPGLEHD
| |
|
| |
|
| >gi|121525100|ref|ZP_01658036.1| conserved hypothetical protein [Parvibaculum lavamentivorans DS-1]
| |
| MTSPLARQIARLIEQTGPIPLSQYMALALGHPEHGYYMTRDPLGARGDFVTAPEISQMFGELVGLWLADQ
| |
| WLEQGSPKPFVLAELGPGRGTLMADALRAIAAVPHMVEAASIHLVETSPVLRNAQSKRIPQAHWHEHVDD
| |
| LPDLPLFLVANEFFDALPVTQYQRTERGWCERFVSMAEGRFVPVLAPVPLADDSGLPAAMKAAQEGSIAE
| |
| VSPASTSITETIAHRIARRGGAALVIDYGHVSSAPGDTLQALRDHKFADPFEAPGEADLTAHVDFEALSH
| |
| AASAAGAAAHGAVEQGRFLMALGIEARAEALSRNATPAQREDIASAMQRLTARDGMGSLFKVLGITPRGA
| |
| PSPAGF
| |
|
| |
|
| >gi|75676687|ref|YP_319108.1| Protein of unknown function DUF185 [Nitrobacter winogradskyi Nb-255]
| | BLASTP results produced 47 multiple aligned sequences to the bacterial sequence of the 1ZKD protein. |
| MRRRARIRALQPRSIVTEPAPLLTYIKKLIKTSGPLPVWRYMQLCLTHPEHGYYIARDPLGREGDFVTSP
| | The results are as follow [[BLASTP results]]. |
| EVSQMFGELLGLWAASVWRMMGSPDPLRLIELGPGRGTLMADALRALRVLPPMYESLSVHMVEINPVLVE
| |
| KQMAALSDAPNIEWHTSLDQVPQGPAIILANEYFDVLPVHQMVRRDGGWHERVVDIDGSGQLVFGVSAEP
| |
| TPRFDVLLPPLVRAAPVGAIFEWRPDAEMMSIATRVRDNGGAALIIDYGHVRSDAGDTFQAISRHSFADP
| |
| LKYPGRVDVTAHVDFEALARAAEDVGARVHGPVPQGEFLRRLGIEARAVNLMAKATPELSDDIATALKRL
| |
| TEGGRGGMGSMFKVIGVSDPSLSVLVGLSDQAHGGGIRTP
| |
|
| |
|
| >gi|89359500|ref|ZP_01197321.1| conserved hypothetical protein [Xanthobacter autotrophicus Py2] | | The highlighted sequences show the 1ZKD protein sequence data and the closest match or best aligned sequence (>gi|39937419|ref|NP_949695.1| DUF185 [Rhodopseudomonas palustris CGA009]). |
| MAVGAAGRRRRRPSALRPEAQAGRVTTPLSKEISALIAAEGPMPLSRYMALCLGHPRHGYYMTRDPLGAR
| |
| GDFTTAPEISQMFGELLGLWAVAQWQAMGSPPAFRLVELGPGRGTLMADALRAARLVPDFGAAARIHLVE
| |
| TSPVLRAAQARTLAAHADRVSWHDRVEEVPDGPALVLANEFFDALPIDQYVFHAGHWHERRVGLDDGGRL
| |
| VLGLDPAPSRAAPAFAAHLPPPAEGVVLEHLESGPARALSERLKTQGGAALIIDYGHAGGYGDTFQALEQ
| |
| HRFADPLAAPGNADLTAHVDFSALARIGRAAGLRAFGPLEQGAFLARLGLAQRAERLKRDATDELRAGVD
| |
| AAARRLAGDGAGEMGRLFKVLVLAHPEIGLPPAFDSTEEWVR
| |
|
| |
|
| >gi|115523453|ref|YP_780364.1| protein of unknown function DUF185 [Rhodopseudomonas palustris BisA53]
| |
| MTDQPLHDTIKKLIRSAGPMPVWRYMELCLTHPEHGYYVSRDPLGREGDFITSPEVSQMFGELLGLWAAS
| |
| VWKAIGSPQQVRLIELGPGRGTLMADAMRALRVLPPLYQAISVHLVEINPVLRDKQRDTLANLSNVAWHA
| |
| DLDEVPGGTSIIFANEYFDVLPVHQAVRGEHGWHERVIEIDAEGDLTFGAAAEPIPQFEVLLPPLVRAAP
| |
| PGAVFEWRADSEIMKIASRVRDEGGAALIIDYGHLRSDAGDTFQAIAKHSFADPLANPGQADVTAHVDFQ
| |
| ALAQAAEAVGARVHGPVTQGEFLRRLGIETRALALMAKASHEISEDVANALKRLTGGGRGGMGSMFKVIG
| |
| VSEADLTEVTGLSDAVRAEVGA
| |
|
| |
|
| >gi|121715340|ref|XP_001275279.1| DUF185 domain protein [Aspergillus clavatus NRRL 1]
| | === Clustal X === |
| MNNARRAWTRHVRACQPRNLRLGSHRCSSTFDQRQWSTPLAKTLANAIKITGPIPISAFMRQVLTSPEGG
| |
| YYTTRPEGGGEVFGKKGDFVTSPEISQVFGELVAVWTITEWMAQGRKRSGVQLIEVGPGKGTLMDDMLRT
| |
| FQNFKSFSSSIEAIYLVEASPTLREVQKQRLCGDAPMEETDIGHRSTSKYFNVPVIWVEDIRLLPHEEGT
| |
| TPFIFAHEFFDALPIHAFESVPPAPESQTEQSEIMTPTGPAKLHQPMKPANTPQWREIMVTLNPEAVEEN
| |
| KEGEPEFKLTLAKASTPSSLVIPEISERYRKLKSQPGSTIEISPESRVYASDFARRIGGSSQPPRTVNRQ
| |
| DAGPVQPKRVPSGAALIMDYGTMSTIPVNSLRGIQNHRNVPALSSPGQVDVSADVDFIALAEAAIDASEG
| |
| VEVHGPVEQGDFLQVMGIAERMQQLLKGIKDEEKRKTLESGWKRLVERGGGGMGKIYKFMAIIPENGGQR
| |
| RPVGFGGTVQM
| |
|
| |
|
| >gi|86751272|ref|YP_487768.1| Protein of unknown function DUF185 [Rhodopseudomonas palustris HaA2]
| |
| MNDDSPLLAEIKRLIETAGPMPVWRYMELCLAHPEYGYYVSRDPLGREGDFTTSPEISQMFGELIGLWTA
| |
| SVWKAVGEPGVLRLIEIGPGRGTMIADALRALRVLPPLYQSLSVHLVEINPVLRAKQQATLAGIRNVHWH
| |
| EDFAEVPEGPAVVLANEYFDVLPIHQAVKRDGGWHERVIEISASGDLVFGVADDPIPRFEVLLPPLVQMA
| |
| PAGTVFEWRPDNEIMAIAARLRDQGGAALIIDYGHVRSDVGDTFQAIARHSFADPLQHPGGADLTAHVDF
| |
| QALGRAAETIGARIHGPVTQGEFLKRLGIETRALSLMAKASAQVSEDIAGALKRLTGEGRGGMGAMFKVI
| |
| GVSDPSITSLVALSDDAERAAEGQKA
| |
|
| |
|
| >gi|56695809|ref|YP_166160.1| hypothetical protein SPO0907 [Silicibacter pomeroyi DSS-3]
| | The following are some ClustalX images that were produced. |
| MSLTGLLLERIAQQGPLSLADYMAECLLHPEYGYYTTRDPLGVAGDFTTAPEISQMFGELIGLALAQAWM
| |
| DQGRPAPFTLVELGPGRGTLMADALRATRAVPGFHEAARLWLVEASPVLRATQAQALAGHDPQWCDTVSD
| |
| LPAGPLFGVANEFFDALPVRQFQRAGAVWRERLVGARDGALCWGLGAEALQPALAHRLEDTREGDLVELC
| |
| PAAGLILSELASRIAADGGAALIVDYGDWRSLGDTVQALRNHAPADPLADPGQADLTAHVDFEVLAMTAR
| |
| AAGCAHSRLSTQGVFLERLGIAQRAQALARHADEAALDRLITAHRRLTHPEEMGNLFKVLGLYPSDATPP
| |
| PGLEP
| |
|
| |
|
| >gi|90422923|ref|YP_531293.1| protein of unknown function DUF185 [Rhodopseudomonas palustris BisB18]
| | [[Image:ClustalX omit.jpg|thumb|900px|Figure 15. Clustal X image of sequences that produce Gaps|center]] |
| MTEPFSLQDVIKKLIKSAGPMPVWRYMELCLTHPEFGYYVSRDPLGREGDFTTAPEVSQMFGELLGLWAA
| |
| SVWRSIGSPQLVRLIEFGPGRGTMMADALRALRVVPPLFQALHVHLIEINPVLREKQKATLAGAQNLHWH
| |
| ASLDEVPGGSTIIFANEYFDVLPIHQMVRGEHGWHERTVEIDAAERLVFGVAPEPVPHFEQLLPPLVRAA
| |
| PQGAVFEWRPDAEIMKIASRVRDEGGAALIIDYGHPRSDAGDTFQAIARHSFADPLQNPGRADVTAHVDF
| |
| QALARGAQDVGARVHGPVTQGEFLKRLGIENRAVALMAKASLEVSEDVASALKRLVEGGRGGMGSMFKVM
| |
| AVSEPEIEQIAGLSDQPEAARTAAQ
| |
|
| |
|
| >gi|111069170|gb|EAT90290.1| hypothetical protein SNOG_02078 [Phaeosphaeria nodorum SN15]
| |
| MRATSLSLLRTATRCSQPQANDIRRRSAQCAIRYTSSLTSTSSGAERKWSTPLAKMLGEAITTTGPISVA
| |
| AYMRQCLTAPEGGYYTRQTSAGQDQFGTTGDFVTSPEISQVFGELIGIWIYAEWLAQGKKEKVQIIEVGP
| |
| GRGTLMDDVLRTISSFKAFANSIEAIYLVEASPHLQKQQGKLLAGTEELQKSDIGLTAPLKYIPGVNIQW
| |
| CEDIRNIEETSSPFILAHEFFDALPIHVFQNIAQSSIPASSMIMTPTGPIKPKHGATVPKNTWHELVVSP
| |
| TNPYSSAGTITTTSSTSTKQEEKPDFELTVSKTPTPHSLYLPKKSDRYKKLEDTNDAIIEISPESMAYIS
| |
| DFAVRIGGDNPPSKAEPTSSSAKLQRTEPAPFSKPQPAGAALILDYGPANTIPANTFRGIRGHQTVSPFT
| |
| SPGLVDLSADVDFLALAESALDASPGVEVHGPVEQSFFLSTMGIKERAERLLKGAKDEATRQRLETGWKR
| |
| LIDRGPNGMGKTYKAMALLPYIKGSKVRRPVGFGGDIAA
| |
|
| |
|
| >gi|110680664|ref|YP_683671.1| hypothetical membrane protein [Roseobacter denitrificans OCh 114]
| | [[Image:Clustal X.jpg|thumb|900px|Figure 16. Clustal X image of end region of MSA cluster|center]] |
| MSLKDQLIARIKAHGPMSVAEYMGDCLLHPTLGYYTTQHPFGGSGDFITAPETSQMFGELIGLCLVQAWV
| |
| DQGRPSPFALVELGPGRGVLMADILRAAAQVPDFARAAEVILVEASPKLQEIQRDTLKAHAVTFVKDVAS
| |
| LPQCPLFVVANEFFDALPIRQFVRSGPHWRERQVGCDAEQLIFGMGAQTPQPALNARLSDTKEHDLVEYA
| |
| PAAAPIMSELGSRIDTHGGAGLIIDYGDWRSLGDTLQAVRQHEYTGVLDHPGESDLTAHVDFEALAQAVP
| |
| CAFSRLTPQGVFLERLGITQRAQRLAQNLPKDLLEQHIKAHRRLTHPEEMGNLFKVLGLFPHGKAPPAGL
| |
| EI
| |
|
| |
|
| >gi|85704768|ref|ZP_01035869.1| hypothetical protein ROS217_06800 [Roseovarius sp. 217]
| |
| MSGLEAQLRARIAEAGPISLADYMAACLMHPEFGYYATRDPFGAGGDFVTAPEISQMFGELLGLCLAQVW
| |
| LDQGRPARFVLAELGPGRGTLMADVLRATQRVPGFRDAAEVHLVEGSAVLRAAQRRAIAGDVIWHERVES
| |
| LPEGPLYLLANEFFDALPIRQFQRFGDGWRERVVGLSDDRLALGLSGPVAPPALVERLAETREGDVVEIC
| |
| GPGEAVAAEIGARIAGHGGAALIVDYGDWRSLGDTFQAVKGHAPVDPLAAPGLADLTAHVDFEALARAAS
| |
| PAVYTRLTPQGVFLERLGIGARSEVLARNLSGQALENHLAAYQRLTGAEEMGTLFKVLGLYPEGTTPPPG
| |
| LDP
| |
|
| |
|
| >gi|116502505|gb|EAU85400.1| hypothetical protein CC1G_07094 [Coprinopsis cinerea okayama7#130]
| | After running Clustal X many sequences were omitted as they created many gaps in the MSA multiple sequence alignment. In the process, all of the mouse and human comparative sequences were also omitted and this is visible in the evolutionary tree constructed at the end. |
| MQLCLSHPTHGYYMNPNNAVFGTSGDFITSPEISQVFGELVGVWLVSQWADAGTPPAIRLVELGPGRGTL
| | This however allowed the focus of the research into the evolutionary construct of the 1ZKD protein to be more specific in relation to other bacteria’s. |
| MDDILRIVKKFLPEKALTGVHLVETSEALRSVQKAKLGEKCDLHFHNGIHEIPRNPSVYTMLVAHEFFDA
| |
| LPVHVVQKTEAGWNEVMIASNDSLSSSESSPSQPQTQKQGVLRRVLNPLPSPASTLLGNSSLRFRNLPIG
| |
| STIEVSPTSFRIAHQIGRLLSARGLEEKPLDLVEASQQETGVGGCGLVIDYGADHAFGDSFRAFKEHKIV
| |
| DVFHRPGECDITANVDFAYLKEAMTVEPHGPITQADFLERMALQTRVEALVRNASSEERKKVILDAANRL
| |
| VDRSGMGTQYKVLGITSSPKSSSTGVWPFDVQNQALES
| |
|
| |
|
| >gi|126739895|ref|ZP_01755586.1| hypothetical protein RSK20926_14444 [Roseobacter sp. SK209-2-6]
| |
| MSSLEQQLVARIQENGPISLAEYMSECLLHPEFGYYSTRDPFGQSGDFVTAPEISQMFGELLGLCLAQCW
| |
| LDQGAPSPFALVELGPGRGTLMRDLLRATAGVTGFHQAMQVFLVEASPKLQREQAKALEEYDVSWVAEPM
| |
| ELPNLPVFLVANEFFDALPARQFVRDSDGWRERLIGLEEGKLGFGLGSATDQPALAYRLEDTRPGDLVEL
| |
| CSPAATLLEPIADRISTFGGAALIIDYGDWRSLGDTLQALRAHKSTPPLENPGKADLTLHVDFEFLAQST
| |
| KSTGCAHSRVTPQGVFLERLGITERAQALSRALQGEALDTLIAAHRRLTHPEEMGNLFKVLGLYPAQFSP
| |
| PPGLLS
| |
|
| |
|
| >gi|114767217|ref|ZP_01446082.1| hypothetical protein R2601_09240 [Roseovarius sp. HTCC2601]
| | After carefully analyzing the MSA in a clustal X format, the closest available sequence to the protein sequence of 1ZKD was the DUF185 protein sequence from Rhodopseudomonas palustris bacteria. The only differences were the occurrence of '''eight different amino acids''' randomly in the sequence and the '''eight extra amino acids''' at the '3’' or the 'C-terminus' end of the 1ZKD amino acid sequence. |
| MSPLEEILHRRIAAEGPMTIAEYMATCLGHPRYGYYPTRDPLGAAGDFTTAPEISQMFGELLGLCLAQCW
| |
| LEQGRPSSFVLAELGPGRGTLMADATRAMRGVPGMLEAARLHLVETSPRLRDEQHRRLAPLMPVWHDSVA
| |
| NLPEAPLYLLANEFFDALPIRQFLRSGEGWCERVVGLSEGRLAFGLTEPAPHGELEHRLADTREGDLVET
| |
| CAPATGIAEDIGRRIASQGGAALIVDYGSARSLGDTFQAVRRHDKVSPLDAPGTADLTAHVDFGALATAM
| |
| PCATTTLTPQGVFLERLGITDRARALAARLSGAQLDSHVAAHRRLTHPEEMGSLFKTLGAFPEGAAPPPG
| |
| LLDT
| |
|
| |
|
| >gi|86136505|ref|ZP_01055084.1| hypothetical protein MED193_20319 [Roseobacter sp. MED193]
| | Our protein amino acid sequence is '''no. 32''' and the closest matched sequence is of DUF185 amino acid sequence is at '''no. 31'''. |
| MSPLTDQLLARISSDGPISLADFMAECLLHPEHGYYTTRSPFGTQGDFTTAPEISQMFGELLGLSLAQSW
| |
| LNQGAPDTFTLAELGPGRGTLMADLLRATRGVPGFHTALQLYLVEASPNLQEQQAKALARYDATWVDTAD
| |
| ALPQQPLFLVANEFFDALPIRQFVRDGDGWREKRIGLVDGGLGFGLGPAAPQPALEHRLRDTTDGDLVEL
| |
| SPGAAPILSSLAQRIASHGGAALIVDYGDWRSLGDTLQALKSHTPVEPLETPGEADLTAHVDFEVLCSVA
| |
| AGAGCAHSKVTPQGVFLERLGITDRARNLAAGLEGEALESLIAAHRRLTHPSEMGNLFKVLGLTPADIAP
| |
| PPGLNA
| |
|
| |
|
| '''>gi|39937419|ref|NP_949695.1| DUF185 [Rhodopseudomonas palustris CGA009]'''
| | === Protdist === |
| MIDQTALATEIKRLIKAAGPMPVWRYMELCLGHPEHGYYVTRDPLGREGDFTTSPEISQMFGELLGLWSA
| |
| SVWKAADEPQTLRLIEIGPGRGTMMADALRALRVLPILYQSLSVHLVEINPVLRQKQQTLLAGIRNIHWH
| |
| DSFEDVPEGPAVILANEYFDVLPIHQAIKRETGWHERVIEIGASGELVFGVAADPIPGFEALLPPLARLS
| |
| PPGAVFEWRPDTEILKIASRVRDQGGAALIIDYGHLRSDVGDTFQAIASHSYADPLQHPGRADLTAHVDF
| |
| DALGRAAESIGARAHGPVTQGAFLKRLGIETRALSLMAKATPQVSEDIAGALQRLTGEGRGAMGSMFKVI
| |
| GVSDPKIETLVALSDDTDREAERRQGTHG
| |
|
| |
|
| >gi|118591907|ref|ZP_01549302.1| hypothetical protein SIAM614_20945 [Stappia aggregata IAM 12614]
| | [[Protdist results]] and how it looks like. |
| MTGLKDRIKARIATEGPLSVAQYMSVCLGDPDAGYYMTREPFGSEGDFITAPEVSQMFGELIGAACLSAW
| |
| QALGEPAEFQLVELGPGRGTLMADLLRMASLRPAFIKAARLNMVETSPRLREIQTATLSRGPLTPHFRNR
| |
| FQDVPGGPLILVANEFFDALPIHQFVKTARGWQERQIGLSQDGELMFGVGTARLPDDAIPADLSSAPEGA
| |
| IFETQPAANAIAEEIGHRIAGNGGAAILIDYGYLNTAAGDTLQALYKHAYDDVLAHPGEADLTAHVNFEA
| |
| LAAATVRAGAQALAPLTQGEFLLRSGLLERAGALGAGKSHSEQEAIRDAVERLAAPGQMGDLFKVLAVTN
| |
| SGISFPPFDSAS
| |
|
| |
|
| >gi|15889490|ref|NP_355171.1| hypothetical protein AGR_C_4024 [Agrobacterium tumefaciens str. C58]
| | The number at the top of the page indicates the number of sequences uploaded. |
| MTTPLAQRIKSLIRLNGPLSVTDFFSLCLADPEHGYYKSREPFGRSGDFITAPEVSQLFGEMLGVFVVHA
| |
| WQRHGAPAQTQLVEIGPGRGTMMSDMLRVIRRIAPPLYETMRVHLVETSPRLSAIQKETLTAHADRLTWH
| |
| DSFDDVPEGFLLLVANELFDAIPIRQFVRTPQGFRERVVSLDANGELVFSTGLAGIDPTLLPPQPERQQL
| |
| GTVFEVSPAREAVMTAICQRLSVHGGTALAIDYGHLVAGYGDTLQAMRNHAFDPPLAHPGEADLTSHVDF
| |
| ESLVKTAQATGVHVNGALRQGDFLHGLGLKERASALAAKATPDQTLEIAEAVNRLAGEGAGKMGELFKVI
| |
| AVSSPALHLLPFRAVD
| |
|
| |
|
| >gi|84683545|ref|ZP_01011448.1| hypothetical protein RB2654_19268 [Rhodobacterales bacterium HTCC2654]
| |
| MSLADKLRARIEGTGPMSVADFMAECLLDPEHGYYTTRDPFGSAGDFTTAPEISQMFGELVGLCLAQGWM
| |
| DQGSPAPFVLAELGPGRGTLMADILRATRGVPGFHDAARIVLVEASPRLRERQQATLTGYGVTWVDSLED
| |
| APDGPLFLVANEFFDALPVRQFQRDADDWRERQVGLKDGALTFGLGGPTAHAPLDRWTDAQPGDLVELRP
| |
| AADAVMAEIDRRIAAQGGAALVIDYGDWHSLGDTLQAVAKHEAADPLANPGAADLTAHVDFEALALAATR
| |
| LTHSRLTPQGVFLERLGITARAQALAARLEGEPLTRHVAAHRRLTHPDEMGTLFKTLAFVPEGAAMLPGL
| |
| ET
| |
|
| |
|
| >gi|83854800|ref|ZP_00948330.1| hypothetical protein NAS141_08731 [Sulfitobacter sp. NAS-14.1]
| | === Bootstrap values for Bacterial Protein === |
| MTTLRDILHSRIASNGPMRIDEYMATCLLHPTQGYYTTRDPFGTQGDFTTAPEISQMFGELLGLCLAQSW
| |
| IAQDAPSAFTLAELGPGRGTLMADILRATRNVPGFIEAAQITLVEASPTLRDVQAKTLAEHQVIWADGTD
| |
| ALPDQPLFLVANEFFDALPIRQFVRGETSWRERQVGLADGALSFGLGPELPQPALADRLADTTPGDLVED
| |
| CTQLAPILHPVSERIATHGGAALIVDYGDWHSLGDTLQALQGHEKADPLVAPGQADLTAHVDFEKLALAA
| |
| APASYTRITPQGVFLERLGITQRAQTLAKGMTEDALNAHVAAHRRLTHPSEMGNLFKVMGIYPPHHSPPP
| |
| GLEP
| |
|
| |
|
| >gi|118735910|ref|ZP_01584383.1| protein of unknown function DUF185 [Dinoroseobacter shibae DFL 12]
| |
| MADRARPPHRAMTPLAEILAARIAATGPITVAEFMAECLLHPTHGYYTTRTPFGQAGDFTTAPEISQMFG
| |
| ELLGLALAQAWHDQGAPPGAILAEIGPGRGTLMADIRRVLKQVPGAATLRPHLVEASPALRAEQATRVPE
| |
| AVRLDRVEDLPDAPLLLVANEFFDALPIRQFERHAAGWAERQIGLAEGALAFGRAQPAALASLAHRMADT
| |
| GPGDLVETCAPAQPIIAEIAGRIARHGGAAIIADYGDWRSKGDTLQAVRAHRPDPVLAHPGQADLTAHVD
| |
| FEPLAQAARTAGASVSAMIPQGVFLERLGITTRAQALATGLEGAALQSHIAAHRRLTHPEEMGTLFKVLC
| |
| VSPPSAPPVPGSIAPPNPGKPDAP
| |
|
| |
|
| >gi|21434891|gb|AAM53573.1| Aby [Azospirillum brasilense]
| | [[Bootstrap values]] |
| MSDAAPDSLAHHLARRILMDGPLSVAAFMAEALGHPRFGYYMRQDPFGVSGDFTTAPEISQMFGELAGLW
| |
| CVDTWARLGGPAPVHLVELGPGRGTLMQDALRAAALVPAFREATRVHLVETSPTLRARQKETLAGIPVAW
| |
| HDRLEDVPEGPTLILANEFFDALPIRQVQKTNHGWFERLIDIDNTESMDTPRFRFVLEAFGSAGARLIPP
| |
| ALRDAPEGSVVEVSPASQPVARLIGERLAAHPGAALVIDYGYRGGPAVGDTLQALRRHAYAPVLDAPGEA
| |
| DLTAHVDFAAIAAAAREGGAESFGPVDQGDWLVRLGIQPRATALKRSATTKQAADIDSALARLIHRCRPA
| |
|
| |
|
| >gi|99080460|ref|YP_612614.1| protein of unknown function DUF185 [Silicibacter sp. TM1040]
| | The evolutionary tree obtained after bootstrapping. This view of the tree via the Treeview program allows for the analyzing of the the organisms that are in close sequence proximity as our sequence. |
| MSLMQSLRRRIELDGPMTVADYMSECLLHPDYGYYTTAPAIGAEGDFITAPEISQMFGELLGLVLVQSWL
| |
| DQGRPQPFTLAELGPGRGTLMADMLRATRAVPGFHEAMELLLIEASPRLRDLQRQALAPYAPRWVPSVED
| |
| LPQHPLFLVANEFFDALPIRQFQREGNQWRERRVGLAEDASGLTLGLGAPAPQPALAHRLEDTKDGDLVE
| |
| HCEVAAVVTEAIAQRIGDHGGVALLVDYGDWRSLGDTLQALRAHAPTDPLAEPGQADLTAHVDFEAICTA
| |
| ASATGCAHTRLTPQGVFLERLGITDRANALASGAAGEPLAQIIAAHRRLTHPEEMGNLFKVLGLYPAKFA
| |
| PPAGLEK
| |
|
| |
|
| >gi|126733062|ref|ZP_01748818.1| hypothetical protein SSE37_14379 [Sagittula stellata E-37]
| | [[Image:Tree with names.jpg]] |
| MSALKDIITRQISRTGPLTLADYMALCLSHPEHGYYATRDPLGAEGDFTTAPEISQMFGELIGLALAQSW
| |
| MDQGAPTRFVLSELGPGRGTLMADALRATTRVPGFHDALELHLVETSPALRAEQAARLPDATWHESVASL
| |
| PEAPLFLIANEFFDALPIRQFLRHAQGWQERVVGLKDGQPTLGLTDPAPHDALDHRLADTEPGQIVENCA
| |
| PAQAIVQETGRRIASHGGTALIVDYGDWRSRGDTFQALYRHKPAEPFARPGEADLTAHVDFEALAKAAHP
| |
| AAHSALTPQGVFLEHLGITARAQALARRLGGAALESHVAAHRRLTHPGEMGSLFKVLALFPHDAPPPPGT
| |
| GLPADPS
| |
|
| |
|
| >gi|84515351|ref|ZP_01002713.1| hypothetical protein SKA53_01796 [Loktanella vestfoldensis SKA53]
| |
| MTTLADLLLTRIARDGPISIASFMTDALMHPAHGYYATRDPFGAAGDFITAPEISQMFGELIGLSLAQAW
| |
| LDQGAPDPVTLAELGPGRGTLMADILRATAAVPGFHAAVTVHFVETSPHLRALQAERVPQATWHDRIDTL
| |
| PDAPLLLVANEFFDALPIRQFVRAGAGWRERMVGAQDGTLCFGLSDAAALAVLTPRLDDTQDGDLVEHCP
| |
| ALPGIVAAIAGRIATNGGAALVIDYGDWQSLGDTFQALAGHAPTDPLAAPGAADLTAHVDFAAIAAHAAP
| |
| ARHSRLTPQGVFLERLGITARALKLASGLTGEALDAHVAAHRRLTHPAEMGDLFKVMALYPATAMPPPGL
| |
| DP
| |
|
| |
|
| >gi|83941322|ref|ZP_00953784.1| hypothetical protein EE36_03798 [Sulfitobacter sp. EE-36]
| |
| MTTLRDILHSRIASNGPMRIDEYMATCLLHPTQGYYTTRDPFGTQGDFTTAPEISQMFGELLGLCLAQSW
| |
| LAQDAPSAFTLAELGPGRGTLMADILRATRNVPGFIEAARITLVEASPTLRDVQAKTLAGHQVIWADGTD
| |
| ALPDQPLFLVANEFFDALPIRQFVRGETSWRERQIGLADGALSFGLGPELPQPALADRLADTKPGDLVED
| |
| CTQLAPILHPVSERIATHGGAALIVDYGDWHSLGDTLQALQGHEKADPLAAPGQADLTAHVDFEKLALAA
| |
| APASHTRITPQGVFLERLGITQRAQTLAKGMTEDALNAHVAAHRRLTHPSEMGNLFKVMGIYPPHHSPPP
| |
| GLEP
| |
|
| |
|
| >gi|114770207|ref|ZP_01447745.1| hypothetical protein OM2255_11240 [alpha proteobacterium HTCC2255]
| |
| MTALSNIIKKQIKRFGPMPVSEYMTLCLLHPEHGYYTNRDALGATGDFTTAPEISQMFGELIGLSIAQSW
| |
| IDQEMPTPFILAELGPGNGTLMADILRATKSVPNFHASMDLHLIEASPEMRKRQETALNGFNVTWLNYFS
| |
| ELPQKPLFLIANEFFDCLPIKQYRRTDEGWQEQMIAVENEQLHFILGTATSEEVFSKTNDVPSADMLEVS
| |
| PPTVAFASAIGEHIQGNGGCAIIVDYGEWDSDGDSLQALKDHRKIDPLTHCGTADLTAHVSFKDLTNAAS
| |
| KYAKVSSTIPQGILLERLGITQRAQTLAKNMSGKKLENHISAHKRLTHPDEMGSLFKAIAIIPENTDLPA
| |
| GFNE
| |
|
| |
|
| '''>gi|67464609|pdb|1ZKD|A Chain A, X-Ray Structure Of The Putative Protein Q6n1p6 From Rhodopseudomonas Palustris At The Resolution 2.1 A , Northeast Structural Genomics Consortium Target Rpr58'''
| | === Evolutionary Tree === |
|
| |
|
| MIDQTALATEIKRLIKAAGPXPVWRYXELCLGHPEHGYYVTRDPLGREGDFTTSPEISQXFGELLGLWSA
| | [[Image:Tree wit bootstrap.JPG|900px]] |
| SVWKAADEPQTLRLIEIGPGRGTXXADALRALRVLPILYQSLSVHLVEINPVLRQKQQTLLAGIRNIHWH
| |
| DSFEDVPEGPAVILANEYFDVLPIHQAIKRETGWHERVIEIGASGELVFGVAADPIPGFEALLPPLARLS
| |
| PPGAVFEWRPDTEILKIASRVRDQGGAALIIDYGHLRSDVGDTFQAIASHSYADPLQHPGRADLTAHVDF
| |
| DALGRAAESIGARAHGPVTQGAFLKRLGIETRALSLXAKATPQVSEDIAGALQRLTGEGRGAXGSXFKVI
| |
| GVSDPKIETLVALSDDTDREAERRQGTHGLEHHHHHH
| |
|
| |
|
| >gi|83859400|ref|ZP_00952921.1| hypothetical protein OA2633_13385 [Oceanicaulis alexandrii HTCC2633] | | '''>>> Brown colored branches''' consists of organisms from a Bacterial lineage, and most of them happen to be gram-negative bacteria. Most of the bacteria’s in the branches seem to be from the alpha proteobacteria family. Some of bacteria also show similarities in their ability for nitrogen fixation namely Rhodopseudomonas palustris, Bradyrhizobium japonicum, Agrobacterium tumefaciens and Azospirillum brasilense. |
| MSDDEFRPAQMISERLAERIRTEGSLSVAAFMAEALFHPMAGFYATKDPLGAANDFITAPEISQMFGELL
| | |
| GLWAAECWMQMGAPSRFELIELGPGTGRMMSDMLRAGRAAPGFLDAVHVTLIEASPALKMVQGQTLASAS
| |
| VPINWAKDFDKAPSGPAVVIGNEFLDCLPIRQAIRHKGQWRERVVTLHPEDEARFVYGLGPVLGEADVAF
| |
| IAPGLREADDGTLVELRPGDQQQIDQLAARFDRDPGYALFVDYGSAKPETGDTLQAIRAHQKVDPLDAPG
| |
| TADLTAWVDFDRLLRLGEDAGLSAFGPMTQGDFLTELGIEQRAAVLSRSVDEAGQAKLKRQMHRLVSPED
| |
| MGTLFKLAAFSSEGLPPAPGIAPFKRSR
| |
|
| |
|
| | '''>>> Green colored branches''' consist of organisms from the Fungi kingdom, mostly found growing in the soil. |
|
| |
|
|
| |
|
| | '''>>> Blue colored branches''' consist of organisms from the Plantae kingdom, some showing affinity to being associated with yeast. |
| | |
|
| |
|
| | '''>>> Red dots''' denote branches/lineages with bootstrap values of more than 75%, which signifies very high confidence on the branching of the organisms in the tree. |
|
| |
|
|
| |
|
| Line 671: |
Line 424: |
|
| |
|
| Return to [[Report on 1zkd]] | | Return to [[Report on 1zkd]] |
| | |
| | |
| | [[http://compbio.chemistry.uq.edu.au/mediawiki/index.php/Discussion_%281zkd%29 Discussion]] |
Structure of Hypothetical Protein LOC55471 Isoform 1
Comparing Structure of Proteins
Dali Results
Dali shows a few proteins with similar structure to 1zkd. They are 2ex4 and 1im8 which shows the highest Z-value of 11.7 and 11.6 respectively. The higher the Z-value the more significant is the results. However, they are only 10-12% identical to the query protein. Nevertheless, these 2 proteins are used to compare with the query protein as these 10-12% identity may be at the binding site or ligand which will determine the functions. 2ex4 is a human methyltransferase with S-adenosylhomocysteine and 1im8 is found to be a methyltransferase with a bound S-adenosylhomocysteine from the crystal structure of YecO from Haemophilus influenzae (HI0319).
SUMMARY: PDB/chain identifiers and structural alignment statistics
NR. STRID1 STRID2 Z RMSD LALI LSEQ2 %IDE REVERS PERMUT NFRAG TOPO PROTEIN
1: 3027-A 1zkd-A 56.8 0.0 349 349 100 0 0 1 S STRUCTURAL GENOMICS, UNKNOWN FUNCTION duf185 (rhodops
2: 3027-A 2ex4-A 11.7 3.0 185 221 12 0 0 22 S TRANSFERASE adrenal gland protein ad-003 (homo sapien
3: 3027-A 1im8-A 11.6 3.2 178 225 10 0 0 18 S TRANSFERASE yeco (methyltransferase, hypothetical pro 4: 3027-A 2gb4-A 10.8 3.3 184 231 13 0 0 19 S TRANSFERASE thiopurine s-methyltransferase (thiopurine
5: 3027-A 2fk7-A 10.7 3.8 186 277 14 0 0 19 S TRANSFERASE methoxy mycolic acid synthase 4 (mycobact
6: 3027-A 2ob1-A 10.2 3.9 196 319 9 0 0 23 S TRANSFERASE leucine carboxyl methyltransferase 1 (prot
7: 3027-A 2f8l-A 10.0 3.7 182 318 8 0 0 22 S STRUCTURAL GENOMICS, UNKNOWN FUNCTION hypothetical pro
8: 3027-A 2avn-A 10.0 3.7 183 242 11 0 0 20 S STRUCTURAL GENOMICS, UNKNOWN FUNCTION ubiquinoneMENAQU
9: 3027-A 2bzg-A 9.9 3.4 182 226 13 0 0 20 S TRANSFERASE thiopurine s-methyltransferase (thiopurine
10: 3027-A 2aot-A 9.8 4.3 182 285 13 0 0 23 S TRANSFERASE histamine n-methyltransferase (hmt) (homo
Alignment with Known Proteins
1zkd is an unknown protein, and by using proteins similar to it, the functions of this unknown protein can be predicted. With 2ex4 and 1im8 showed by Dali to be the most similar, other tools are used to determine the similarity. Combinatorial Extension Method is used. Below shows the sequence alignment and structure alignment of the unknown protein with the proteins obtained from dali:
2ex4
Alignment with 2ex4
1ZKD:A 24/25 WRYXELCLGHPEHGYYV--TRDPLGREGDFTTSPEISQXFGELLGLWSASVWKAAD-EPQ
2EX4:A 24/7 IEDEKQFYS----KAKTYWKQIPPTVDGMLGGYGHISSIDINSSRKFLQRFLREGPNKTG
1ZKD:A 81/82 TLRLIEIGPGRGTXXADALRALRVLPILYQSLSVHLVEINPVLRQKQQTLLAGI-RNIHW
2EX4:A 80/64 TSCALDCGAGIGRITKRLLLPL--------FREVDMVDITEDFLVQAKTYLGEEGKRVRN
1ZKD:A 140/141 HD-----SFEDVPEGPAVILANEYFDVLPIHQAIKRETGWHERVIEIGASGELVFGVAAD
2EX4:A 132/116 YFCCGLQDFTPEPDSYDVIWIQWVIGHLT-------------------------------
1ZKD:A 195/196 PIPGFEALLPPLARLSPPGAVFEWRP--DTEILKIASRVRDQGGAALIIDYG--HLRSDV
2EX4:A 161/145 ------------------------DQHLAEFLRRCKGSL-RPNGIIVIKDNMAQE-----
1ZKD:A 251/252 GDTFQAIASHSYADPLQHPGRADLTAHV---DFDALGRAAESIGARAHGPVTQG
2EX4:A 191/175 GVILDD---------------VDSSVCRDLDVVRRIICSAG---LSLLAEERQE
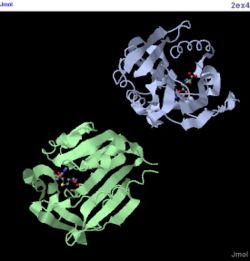
Figure 3. Structure of 2ex4
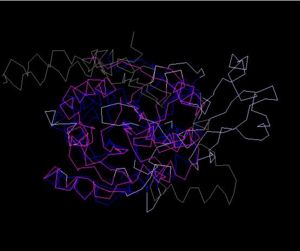
Figure 4. Structure Alignment with 2ex4 (Blue:1zkd, Purple: 2ex4)
Alignment Length: 294
Gaps (average per molecule): 53.5
Sequence Identity: 14.4%
RMSD min – max: 3.03A
1im8
Alignment with 1im8
1ZKD:A 59/60 QXFGELLGLWSASVWKAADEPQTLRLIEIGPGRGTXXADALRALRVLPILYQSLSVHLVE
1IM8:A 42/40 SNIITAIGXLAERFV-----TADSNVYDLGCSRGAATLSARRNI-----NQPNVKIIGID
1ZKD:A 119/120 INPVLRQKQQTLLAGI---RNIHWHD--SFEDVPEGPAVILANEYFDVLPIHQAIKRETG
1IM8:A 92/90 NSQPXVERCRQHIAAYHSEIPVEILCNDIRHVEIKNASXVILNFTLQFLP----------
1ZKD:A 174/175 WHERVIEIGASGELVFGVAADPIPGFEALLPPLARLSPPGAVFEWRP--DTEILKIASRV
1IM8:A 142/140 ---------------------------------------------PEDRIALLTKIYEGL
1ZKD:A 232/233 RDQG--GAALIIDYG
1IM8:A 157/155 ---NPNGVLVLSEKF
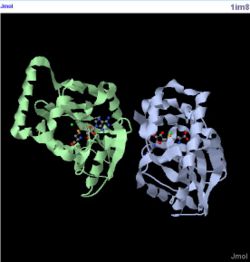
Figure 5. Structure of 1im8
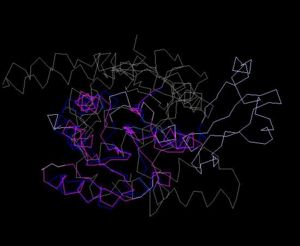
Figure 6. Structure Alignment with 1im8(Blue:1zkd, Purple: 1im8)
Alignment Length: 195
Gaps (average per molecule): 38.5
Sequence Identity: 11%
RMSD min – max: 2.3A
Ligand and Binding Sites
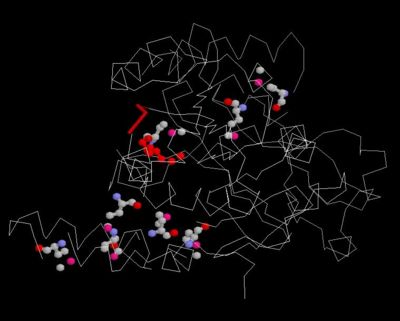
Figure 8. Conserved regions
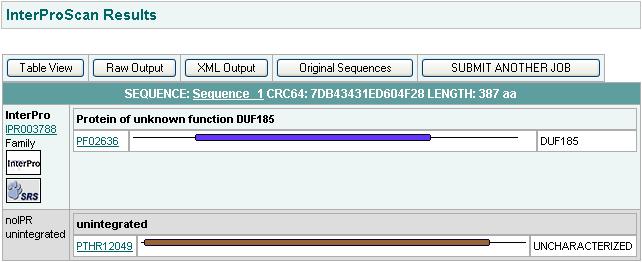
Domain
InterPro Results
Pfam Results
DUF185: domain 1 of 1, from 64 to 299: score 227.1, E = 3.9e-65
*->alArwllveykllgyPYadlnlvElGaGrGtaielmsdlLryiarlv
+l++w + ++k+ ++P l+l E+G+GrGt +m+d+Lr+ r+
query 64 LLGLWSASVWKAADEP-QTLRLIEIGPGRGT---MMADALRA-LRVL 105
PdvyartryylvEiSprLaarQketLapkvaplGhdskveieatdlsglv
P +y+ ++++lvEi+p L+++Q++ La ++ ++
query 106 PILYQSLSVHLVEINPVLRQKQQTLLA-----------------GIR-NI 137
rWhdasileedPdgvptvliaNEVlDalPHDlvrfdkrgggwyErhVlvd
Whd s +e++P+g p v++aNE +D lP +++ +kr+ gw+Er V ++
query 138 HWHD-S-FEDVPEG-PAVILANEYFDVLP--IHQAIKRETGWHER-V-IE 180
ldgdfrlvysqeldplaglaltlreaaldPVKstkklvpsalskllpkll
+ ++lv+++++dp g+ ++l
query 181 IGASGELVFGVAADPIPGFEAL------------------------LPPL 206
ppaeevgygtEvYsParllellqalaerLpahrGrlLaiDYGhlaseyyh
+ +g+++E+ P e+l+++ + + +G++L+iDYGhl+s
query 207 ARLSPPGAVFEW-RPDT--EILKIASRVRD-QGGAALIIDYGHLRSD--- 249
prrksalaaemfngtllqayrqhahddpltnpssllVlyStvaqGlaDiT
g+++qa+ h + dpl +p G+aD+T
query 250 ------------VGDTFQAIASHSYADPLQHP------------GRADLT 275
ahVDFtalaradqyqtaakaagdlkvlgvet<-*
ahVDF+al +aa +g + + g+ t
query 276 AHVDFDALG------RAAESIG-ARAHGPVT 299
Domain DUF 185 has been identified by InterPro and Pfam as show above. In Pfam the E value of 3.9e-65 gives significant results showing that it is not by chance nor random that the match made was DUF185. DUF 185 belong to the family of RNA methyltransferase.
Function of Hypothetical Protein LOC55471 Isoform 1
ProFunc analysis reveals methyltransferase activity as the most likely biochemical function
By using ProFunc (Laskowski et al, 2005) the most likely biochemical function of the unknown bacterial Protein 1zkd was determined as Methyltransferase.
Matching structures were determined by SSM Secondary Structure Matching (Krissinel & Henrick, 2004) showing possible matches with 9 Methyltransferases from both human and bacteria (Fig.9).
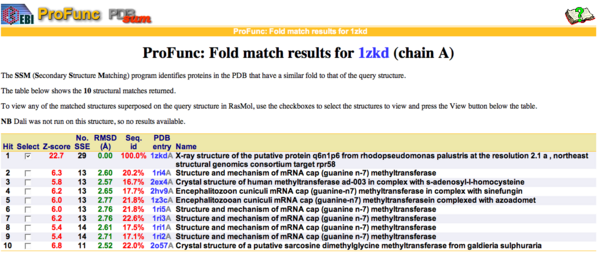
Figure 9. SSM results showing ten sequences with a sequences id around 20 % with higher matching folds.
Ligand Template Matches LIG (Laskowski et al, 2005) revealed a probable match with the Protein-l-isoaspartate o-methyltransferase 1dl5 (Fig.10).
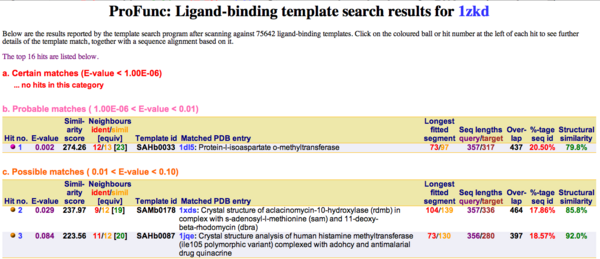
Figure 10. LIG results support the hypothesis of 1zkd being a methyltransferase.
REV Reverse Template Matches (Laskowski et al, 2005) also showed probable matches for several methyltransferases (Fig.11).
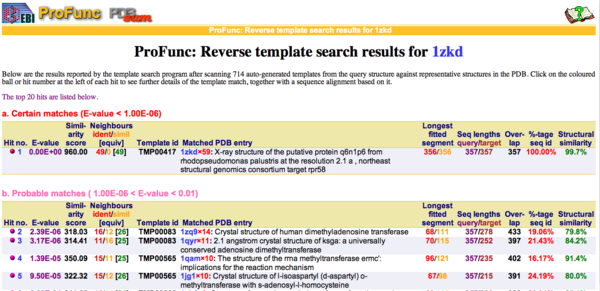
Figure 11. REV results showing five probable matches, which are all methyl or dimethyltransferases.
Superfamily program searches against a library of Hidden Markov Models HMMs (Gough et al, 2001; Madera et al, 2004) derived from SCOP families revealed similarities to the superfamily S-Adenosylmethionine-dependent Methyltransferases (E-value 6.69e-06). No DNA binding motifs (helix-turn-helix) were found in the ProFunc search.
Genomic context of the 1izkd gene
Genomic context of 1zkd in the genome of Rhodopseudomonas palustris from the NCBI Entrez Gene database shows a genomic co-localisation with another transferase, an oxidase, a kinase and another hypothetical protein (Fig.12).

Figure 12. The RPA4359 gene of the protein 1zkd is co-located with an upstream prolipoprotein diacylglyceryl transferase gene (1gt) and downstream with a multicopper polyphenol oxidase (RPA4360), a ribose-phosphate pyrophosphokinase (ribP) and another hypothetical protein of unknown function gene (RPA4361).
Localisation of 1zkd orthologs in the cell
Nucleo (Nuclear Protein Localisation Prediction) predicted a chance of 0.07 for the mouse ortholog and a chance of 0.20 for the human ortholog of 1zkd to be located in the nucleus (Hawkins et al, 2006).
LOCATE data was available for the mouse ortholog showing that it is a soluble, non-secreted protein with higher scores for a localisation in mitochondria or the cytoplasm (Fink et al, 2006).
Expression profiles of mouse and human orthologs
Expression profile data of the mouse and human ortholog were suggested by analysis of EST counts from NCBI UniGene database (http://www.ncbi.nlm.nih.gov/sites/entrez?db=unigene). ESTs were found in diverse tissues including brain, liver, lung, muscle and endocrine system showing that the target protein is expressed in a wide range of different cells (Fig.13a,b).
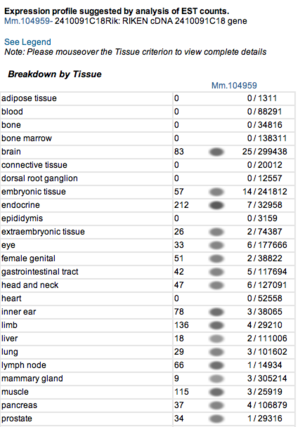
Figure 13a. Expression profile of the mouse ortholog.
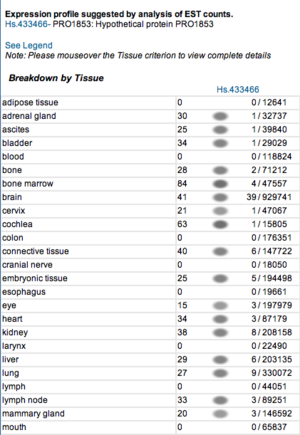
Figure 13b. Expression profile of the human ortholog.
Electrostatic properties of the 1zkd protein surface
Electrostatic properties and surface charges of 1zkd were modelled using Adaptive Poisson-Boltzmann Solver APBS (Baker et al, 2001) and visualisation was performed by using Pymol (http://www.pymol.org). According to the resulting model, the 1zkd protein got a mostly negatively charged surface (Fig.14a,b), indicating that interactions with the negatively charged backbone of nucleic acids are rather unlikely.
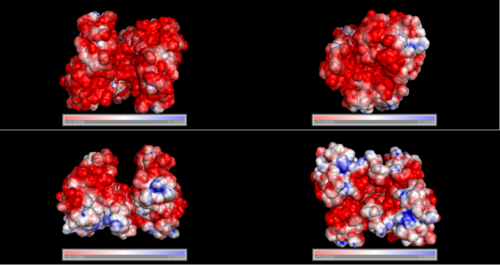
Figure 14a. Surface charges of 1zkd as a dimer. Red colour indicating negative charges, blue colour indicating positive charges.
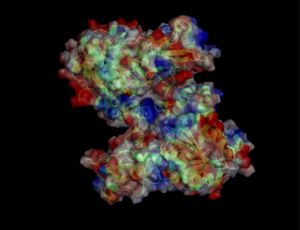
Figure 14b. Surface Charges of Protein. Red colour indicating negative charges, blue colour indicating positive charges
Evolution of Hypothetical Protein LOC55471 Isoform 1
BLAST P
BLASTP results produced 47 multiple aligned sequences to the bacterial sequence of the 1ZKD protein.
The results are as follow BLASTP results.
The highlighted sequences show the 1ZKD protein sequence data and the closest match or best aligned sequence (>gi|39937419|ref|NP_949695.1| DUF185 [Rhodopseudomonas palustris CGA009]).
Clustal X
The following are some ClustalX images that were produced.

Figure 15. Clustal X image of sequences that produce Gaps

Figure 16. Clustal X image of end region of MSA cluster
After running Clustal X many sequences were omitted as they created many gaps in the MSA multiple sequence alignment. In the process, all of the mouse and human comparative sequences were also omitted and this is visible in the evolutionary tree constructed at the end.
This however allowed the focus of the research into the evolutionary construct of the 1ZKD protein to be more specific in relation to other bacteria’s.
After carefully analyzing the MSA in a clustal X format, the closest available sequence to the protein sequence of 1ZKD was the DUF185 protein sequence from Rhodopseudomonas palustris bacteria. The only differences were the occurrence of eight different amino acids randomly in the sequence and the eight extra amino acids at the '3’' or the 'C-terminus' end of the 1ZKD amino acid sequence.
Our protein amino acid sequence is no. 32 and the closest matched sequence is of DUF185 amino acid sequence is at no. 31.
Protdist
Protdist results and how it looks like.
The number at the top of the page indicates the number of sequences uploaded.
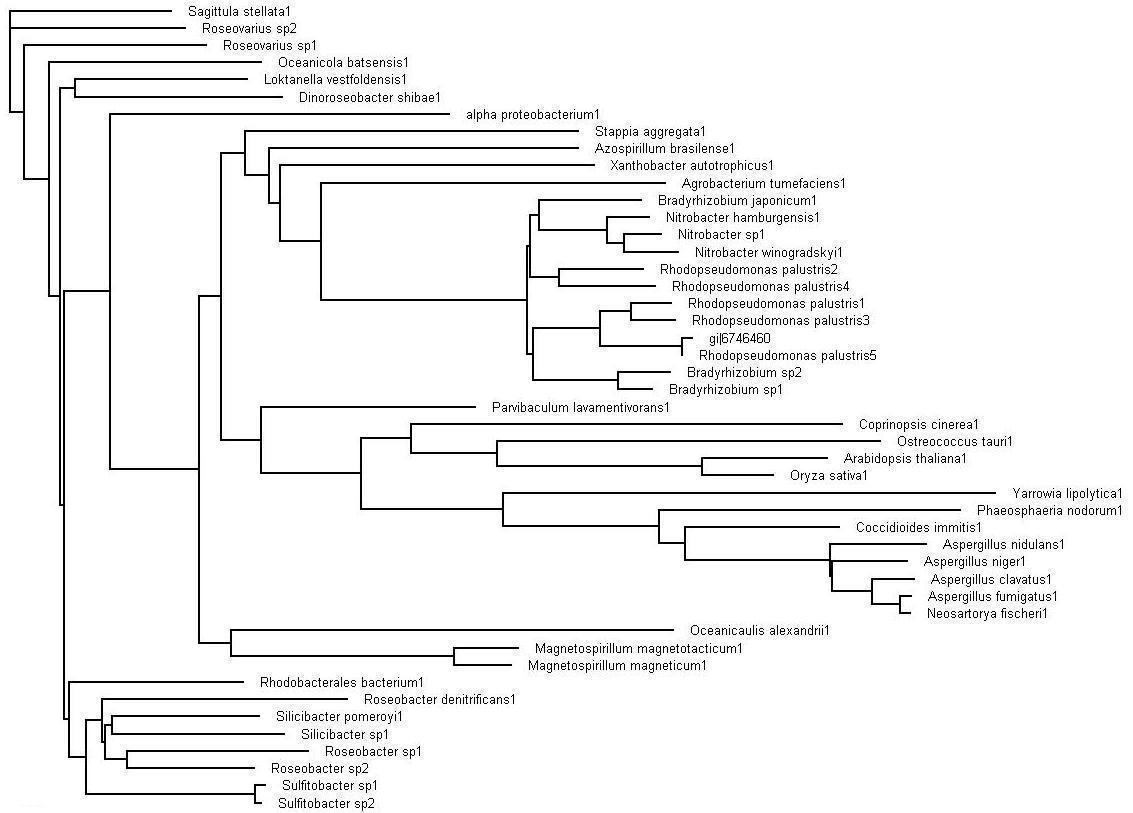
Bootstrap values for Bacterial Protein
Bootstrap values
The evolutionary tree obtained after bootstrapping. This view of the tree via the Treeview program allows for the analyzing of the the organisms that are in close sequence proximity as our sequence.
Evolutionary Tree
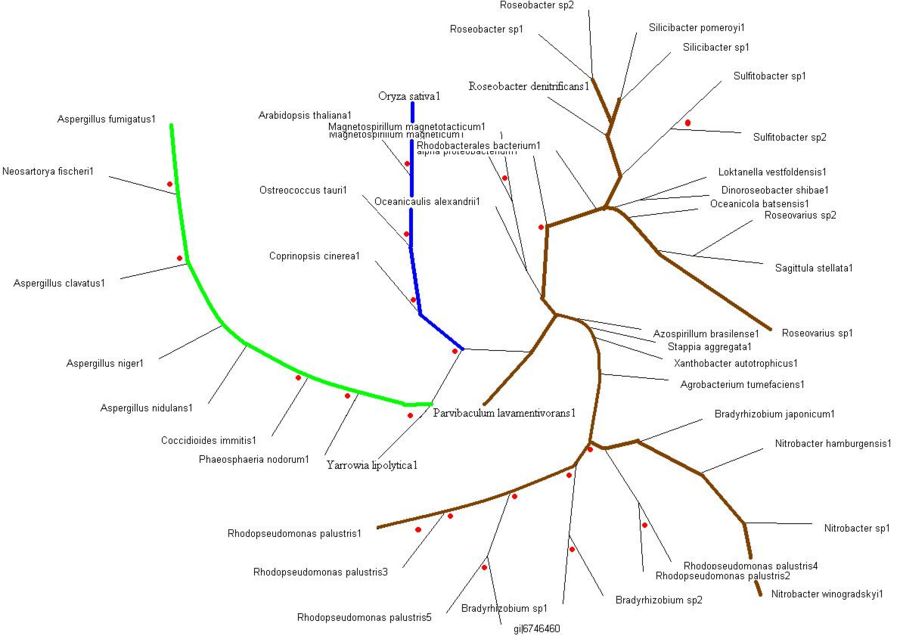
>>> Brown colored branches consists of organisms from a Bacterial lineage, and most of them happen to be gram-negative bacteria. Most of the bacteria’s in the branches seem to be from the alpha proteobacteria family. Some of bacteria also show similarities in their ability for nitrogen fixation namely Rhodopseudomonas palustris, Bradyrhizobium japonicum, Agrobacterium tumefaciens and Azospirillum brasilense.
>>> Green colored branches consist of organisms from the Fungi kingdom, mostly found growing in the soil.
>>> Blue colored branches consist of organisms from the Plantae kingdom, some showing affinity to being associated with yeast.
>>> Red dots denote branches/lineages with bootstrap values of more than 75%, which signifies very high confidence on the branching of the organisms in the tree.
Return to Report on 1zkd
[Discussion]


















